
AlphaTensor
This month’s big boy breakthrough is provided by DeepMind. These people used AI to optimize matrix multiplication efficiency in certain cases. Their model is a success and breaks the limits, offering significantly better algorithms for the first time since 1969.

Matrix multiplication is an extremely common computational procedure; its efficiency affects the costs of many existing technologies and future research. It is also one of the main operations employed in machine learning.
This means savings on time/energy/money/whatever during many phases of work with machine learning, enabling larger models on the long-term scale. However, most importantly, this is yet another powerful case of AI improving the very fundamentals behind the gifts of informational revolution, reassuring us that wonders lie ahead.
Interestingly enough, AlphaTensor is a successor to AlphaZero - DeepMind’s algorithm developing strategies for games that cannot be solved or heuristically optimized. This once again outlines a powerful pattern for AI training - simplify and regularize a real-world problem into a game, then let AI master this abstract but interpretable environment.
Algorithm Distillation
Here comes the meta-learning section! Deepmind proposes Algorithm Distillation approach to teach a model to learn when presented an entirely new context.

Algorithm Distillation relies on the model getting fed "learning histories" that capture learning processes for various tasks. The model then tries to predict actions required to perform a new task in a new environment - and in some cases it presents extreme data-efficiency, achieving good levels of performance for tasks with sparse rewards or in complicated environments.
Prototype Gödel Machine
OK, this is from late September. But pardon me, it’s an outlier! An anonymous paper submitted at International Conference on Learning Representations 2023 claims its authors made something special.
A Gödel machine is a hypothetical program that is capable of rewriting itself to optimize for other tasks. This is exactly what the paper’s creators tried making. They developed a model that has several secondary tasks to optimize for, and a primary task to rewrite itself to improve performance on secondary tasks. These were the results - take a look at some loss curves for one of the secondary tasks.

Certainly, adventures into the Escheresque Gödel-machine-land are among the important aspects when we talk about our ascent to reach and align AGI. We look forward to more papers like this coming out from industry leaders.
If you are a loss curve enjoyer, you can find even more of them in the original source.
Mind’s Eye
Google research implements a wonderful idea: they improve language model inference by letting the AI run a test in an internal physics simulation engine and then interpret the results to formulate the answer.

The metric increases are absolutely fantastic; the model outperforms the Chain-of-Thought methodology presented in this spring’s Google PaLM papers. The human mind does something similar - it creates an abstract recreation of reality which is based on the data received through perception channels, then it makes assessments based on projections within this abstract recreation and forms an output.
This work is a step towards digitized abstract thinking. Right now internal simulation is limited by a pre-defined narrow range of cases. The next stage would be letting a model generalize over making simulations to remove constraints over the method’s use cases.
Now tell me: if we are going for prototype abstract thinking, why aren't there any papers attempting long-term memory in contextual language generation?
Continual Learners
While it is not exactly long-term memory, this paper's authors achieve Continual Learning - their model can take up new tasks while retaining its expertise at previous ones.

The authors argue that Continual Learning emerges with "self-supervision pre-training", and their model combines instuctions in ways it was never trained for, demonstrating "instruction compositionality".
U-PaLM / Flan
U-PaLM is an upgraded version of SoTA language model PaLM that achieves better performance and presents more emergent properties with same number of parameters.

Flan is a modification to language models that enhances their capabilities. Flan-augmented T5 achieves high performance on certain tasks while maintaining low parameter count, while Flan-augmented PaLM and U-PaLM mark a new milestone towards reaching the human expert score.
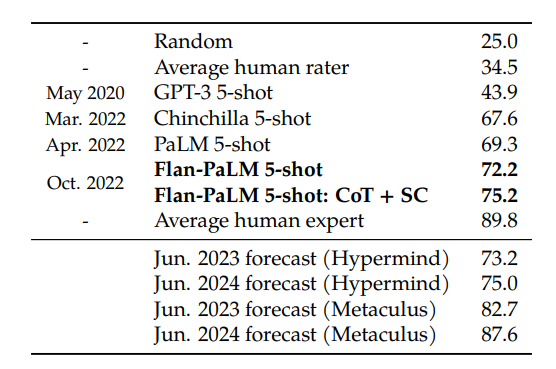
Imagen Video
Welcome back to the generative heaven. Google’s Imagen was known for its functionality akin to OpenAI’s Dalle-2, Midjourney, or bloomingly open-source Stable Diffusion. This time they go a step further and introduce competition for Meta’s Make-a-Video, making their turn in the text-to-video game.
My takeaway from Imagen’s text-to-video is the same as one from their text-to-image: their approach works nicely with words and symbols.

Half a year ago I read from some source that the jumbled words problem is likely to be solved by plainly scaling the generative models. It appears that either Google’s approach has this problem covered, or we are subject to some cherry-picking.
Anyway, people in subreddits and discords will keep blaming google for not releasing any interactive interface for their models. Until they start doing so, we have little evidence as to what extent their examples are representative.
Imagin
Yes, it is related to Imagen. Apparently, this work was created during someone’s internship with the help of the Imagen team. Take a look at this!

You get your result with only one image and one prompt.
A diffusion editing approach that outplays current methods of textual inversion and DreamBooth training (SD nerds will understand). Miraculous. Google didn’t even make an article about this [yet].
This is just a glimpse of the real power that AI can bring to amateur consumer editing software. Minds will be blown.
Phenaki.video
This is another anonymous submission for the ICLR 2023 conference. Yes, it is text-to-video again, but this time it is possible to generate a minutes-long video by writing an entire paragraph describing a sequence of events.

The generator tries to coherently stick contexts together. Same as with current language models, there is no long-term context memory, but chaining short and granular contexts is an interesting move.
AudioLM
Three months ago I spent an evening talking to my father, who is a big fan of classical music, about how he could hear new pieces of music by his favorite but long-gone Chopin or Beethoven.
Being an open and scientifically-oriented person, he is quite skeptical of that being achievable within his lifetime.
I cannot be sure of that as well, but here’s a work that puts a dent in his skepticism. It’s Google again, with an audio-generative network, incorporating a new approach with an underlying language model adding to the generation process.

Most impressive are the examples of how this work’s achievements were transposed into generating piano music. Anyone with experience in music theory understands that this is far from being high quality, but it’s a serious jump from previous attempts. Check out the link with more examples - the bottom table's rightmost column represents AudioLM's true power.
Audio Hypercompression
This overkill research paper from Meta AI reviews a new way to compress audio to take up to 10x less space than standard encoding.

This again proves that the “instant media” phenomenon is coming not only through the appearance of the next-gen internet connection but also through the new ways to compress files.
TabPFN
A new classification algorithm that is extremely efficient and fast. Take a look at how it handles some classification problems (TabFPN is in the right-most column):

Specifically, TabFPN completely outplays other solutions on simple tasks - the less time a classification task is likely to take with an existing algorithm, the higher advantage TabFPN has over it. Numerous applications at the very core of a classic ML problem!
Other News
Meta has proposed a somewhat obvious, but newly implemented architecture to generate translated speech based on the original audio.

Also in speech: OpenAI’s “Whisper” - software for automated speech recognition - is now public. This is good news, as open-source AI proved to work wonders when it comes to both community experimentation and corporative development. I have already seen some examples of previously released OpenAI’s “Clip” being used by Stable Diffusion enthusiasts to reverse engineer prompts for images.
Meanwhile, Stable Diffusion has just received 100M$ in funding. The community keeps creating builds with various functionality. Problem is - none of them are simple enough or have a proper marketing campaign to crawl outside the nerdy modular build market. Right now it’s just punks messing with code and clunky UX, but let’s give it time.
These pieces of software are still out of reach for my friends who use Dalle or Midjourney and don’t own a powerful video card. I think we should pay more attention to peripheral software and services like Lexica.art - a prompt explorer represents a new kind of product that will be widespread in a prompt-engineered future.
Closing words
Thank you for reading this, here is your minimalistic achievement badge for being amazing!

Have a nice day, and see you next time. Rephrase the news for 5-year-olds, then tell your friends, your grandma, and your dog. Not for me, but for AI awareness. Spread the word.